| This is a guest post by Jenkins World speaker Neil Hunt, Senior DevOps Architect at Aquilent. |
In smaller companies with a handful of apps and fewer silos, implementing CD pipelines to support these apps is fairly straightforward using one of the many delivery orchestration tools available today. There is likely a constrained tool set to support - not an abundance of flavors of applications and security practices - and generally fewer cooks in the kitchen. But in a larger organization, I have found that in the past, there were seemingly endless unique requirements and mountains to climb to reach this level of automation on each new project.
|
Neil will be presenting more
of this concept at Jenkins World in
September, register with the code |
Enter the Jenkins Pipeline plugin. My recently departed former company, a large financial services organization with a 600+ person IT organization and 150+ application portfolio, set out to implement continuous delivery enterprise-wide. After considering several pipeline orchestration tools, we determined the Pipeline plugin (at the time called Workflow) to be the superior solution for our company. Pipeline has continued Jenkins' legacy of presenting an extensible platform with just the right set of features to allow organizations to scale its capabilities as they see fit, and do so rapidly. As early adopters of Pipeline with a protracted set of requirements, we used it both to accelerate the pace of onboarding new projects and to reduce the ongoing feature delivery time of our applications.
In my presentation at Jenkins World, I will demonstrate the methods we used to enable this. A few examples:
-
We leveraged the Pipeline Remote File Loader plugin to write shared common code and sought and received community enhancements to these functions.
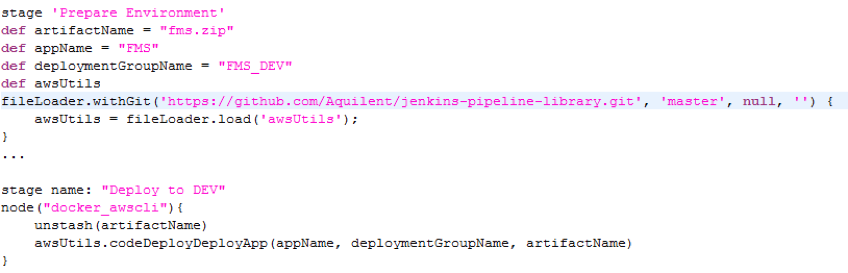
Jenkinsfile, loading a shared AWS utilities function library
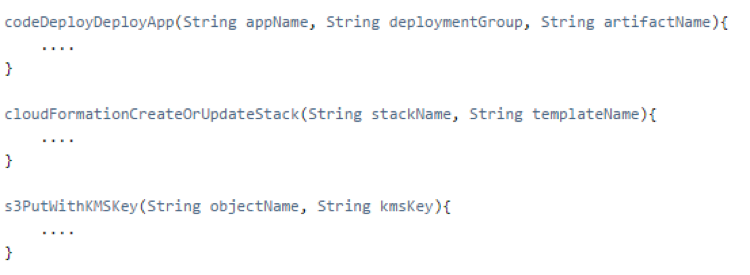
awsUtils.groovy, snippets of some AWS functions
-
We migrated from EC2 agents to Docker-based agents running on Amazon’s Elastic Container Service, allowing us to spin up new executors in seconds and for teams to own their own executor definitions.

Pipeline run #1 using standard EC2 executors, spinning up EC2 instance for each node; Pipeline run #2 using shared ECS cluster with near-instant instantiation of a Docker agent in the cluster for each node.
-
We also created a Pipeline Library of common pipelines, enabling projects that fit certain models to use ready-made end-to-end pipelines. Some examples:
-
Maven JAR Pipeline: Pipeline that clones git repository, builds JAR file from pom.xml, deploys to Artifactory, and runs maven release plugin to increment next version
-
Anuglar.JS Pipeline: Pipeline that executes a grunt and bower build, then runs S3 sync to Amazon S3 bucket in Dev, then Stage, then Prod buckets.
-
Pentaho Reports Pipeline: Pipeline that clones git repository, constructs zip file, and executes Pentaho Business Intelligence Platform CLI to import new set of reports in Dev, Stage, then Prod servers.
-
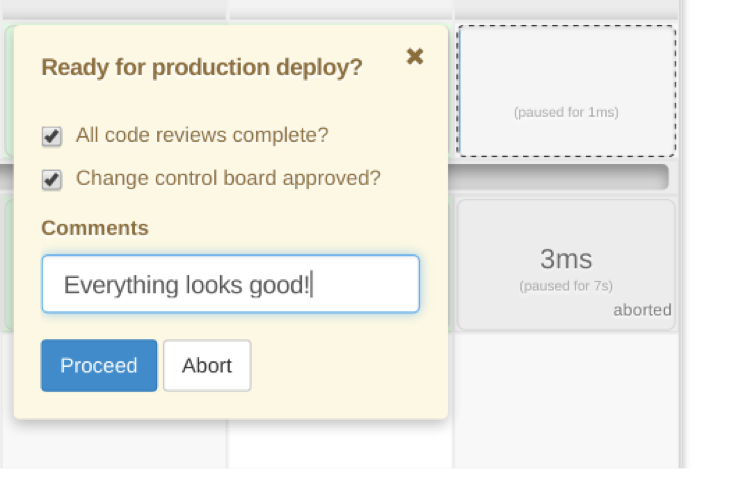
Perhaps most critically, a shout-out to the saving grace of this quest for our security and ops teams: the manual 'input' step! While the ambition of continuous delivery is to have as few of these as possible, this was the single-most pivotal feature in convincing others of Pipeline’s viability, since now any step of the delivery process could be gate-checked by an LDAP-enabled permission group. Were it not for the availability of this step, we may still be living in the world of: "This seems like a great tool for development, but we will have a segregated process for production deployments." Instead, we had a pipeline full of many 'input' steps at first, and then used the data we collected around the longest delays to bring management focus to them and unite everyone around the goal of strategically removing them, one by one.

Going forward, having recently joined Aquilent’s Cloud Solutions Architecture team, I’ll be working with our project teams here to further mature the use of these Pipeline plugin features as we move towards continuous delivery. Already, we have migrated several components of our healthcare.gov project to Pipeline. The team has been able to consolidate several Jenkins jobs into a single, visible delivery pipeline, to maintain the lifecycle of the pipeline with our application code base in our SCM, and to more easily integrate with our external tools.
Due to functional shortcomings in the early adoption stages of the Pipeline plugin and the ever-present political challenges of shifting organizational policy, this has been and continues to be far from a bruise-free journey. But we plodded through many of these issues to bring this to fruition and ultimately reduced the number of manual steps in some pipelines from 12 down to 1 and brought our 20+ Jenkins-minute pipelines to only six minutes after months of iteration. I hope you’ll join this session at Jenkins World and learn about our challenges and successes in achieving the promise of continuous delivery at enterprise scale.

|
Hannah Inman
This author has no biography defined. See social media links referenced below. |